
Когда протокол HTTP только появился, web был устроен достаточно просто. Там в основном размещались простые текстовые странички в формате HTML. Поэтому протокол HTTP версия 1.0 работал в режиме запрос-ответ. Клиент запрашивает web-страницу у сервера, сервер ему эту страницу передает, это позволило сделать протокол достаточно простым.

Первую статью о протоколе HTTP читайте в статье HTTP для чайников.
Однако современный web устроен более сложно. Современные web-страницы включают большое количество других ресурсов. Кроме web-страницы, необходимо загрузить:
- целевой файл;
- файл, который содержит программы, которые будут выполняться на стороне браузера;
- картинки, которые являются составной частью web-страницы;
- возможно видео или аудио.
Кроме этого, некоторые страницы используют какие-то блоки передаваемые с других сайтов. Таким образом, по протоколу HTTP сейчас загружается ни одна страница, а большое количество ресурсов с web-сервера.
Загрузка нескольких ресурсов
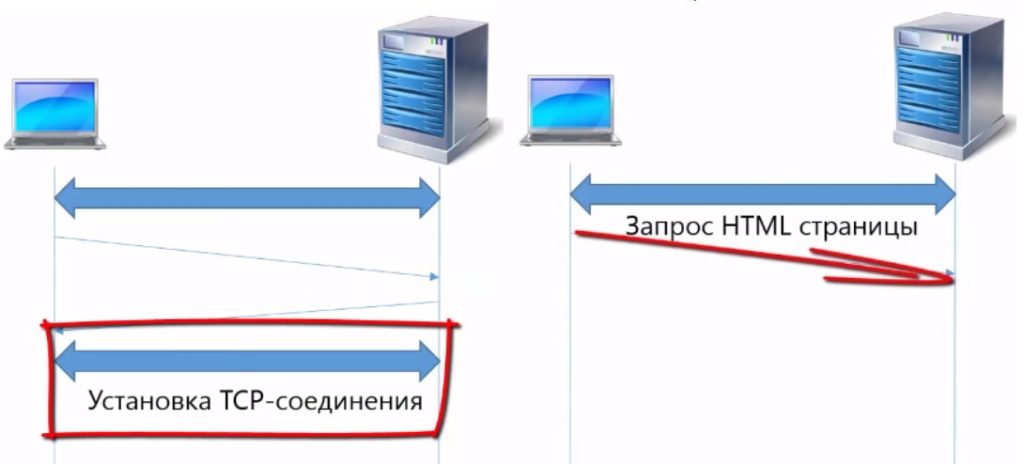
Посмотрим как это реализуется. Прежде чем, что-то загружать с web-сервера, клиенту необходимо установить TCP соединение.

Затем выполняется запрос по протоколу HTTP.

GET возвращает web-страницу, после этого соединение закрывается.

Браузер анализирует содержимое web-страницы, видит, что необходимо загрузить целевой файл, большое количество картинок и другие элементы. Для того чтобы загрузить следующий ресурс, например стилевой файл необходимо открыть новое соединение.
После этого клиент передает запрос HTTP GET на загрузку стилевого файла.
Сервер в ответ передает этот файл.
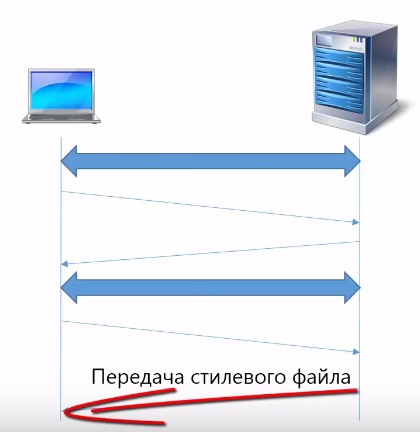
После чего соединение снова закрывается. Таким образом, для того чтобы загрузить каждый элемент web-страницы, необходимо открыть отдельные tcp соединения.
Постоянное соединение в HTTP
Альтернативный подход, который называется постоянное соединение, заключается в том что можно один раз установить соединение tcp и затем использовать его для загрузки различных ресурсов не только HTML страницы, но и стилевых файлов, javascript, картинок и всех связанных ресурсов. TCP соединения разрываются после того, как все ресурсы были загружены.

По-английски постоянное соединение называется HTTP persistent connection или HTTP keep-alive. Использование постоянного соединения позволяет повысить скорость загрузки web-страниц.
- Во-первых, нет необходимости каждый раз устанавливать HTTP соединения, то есть мы не проходим процедуру трехкратного рукопожатия.
- Во вторых, скорость передачи данных при установке нового соединения TCP низкая. Для того чтобы регулировать скорость передачи данных, TCP используют размер окна, чем больше размер окна тем больше скорость передачи данных. Так как при установке соединения, TCP ничего не знает про сеть, то используется маленький размер окна, который увеличивается при получении каждого подтверждения с помощью механизма slowstart, а затем аддитивного увеличения мультипликативного уменьшения. Если мы не открываем каждый раз новое соединение, а используем существующие, то нам не надо каждый раз начинать с маленького размера окна, и мы используем существующее TCP соединение, которое позволяет передавать данные на высокой скорости.
Постоянное соединение в HTTP 1.0
В стандарте HTTP 1.0 не было возможности использовать постоянное соединение. Уже после публикации стандарта был придуман специальный заголовок Connection: keep-alive. Клиент добавляет этот заголовок к запросу, для того чтобы попросить сервер не закрывать соединение после передачи ответа. Если сервер понимает этот заголовок и поддерживает постоянное соединение, он оставляет соединение открытым и добавляет этот заголовок к ответу.
В HTTP 1.0 нет гарантий, что соединение останется открытым, так как этот заголовок не является частью стандарта, то клиент и сервер могут его не поддерживать, а во-вторых у сервера просто может не хватить ресурсов для того чтобы оставить соединение открытым.
GET /tehnologii/protokoli HTTP 1.0
Host: www.rocksmith.ru
Connection:keep-alive
Посылаем запрос http, используя метод GET, хотим получить страничку со статьями по протоколам (/tehnologii/protokoli), которые находятся на сайте (www.rocksmith.ru) по протоколу HTTP/1.0.
Добавляем заголовок Connection:keep-alive для того чтобы попросить сервер не разрывать соединение после того как он передаст нам web-страницу.
Сервер присылает нам ответ
HTTP/1.0 200 OK
Server: nginx
Content-Type: text/htm1; charset=UTF-8
Content-Length: 5161
Connection: keep-alive
Первая строчка статус 200 ОК, означает, что необходимая нам страница найдена. Дальше идут заголовки, и нужный нам заголовок Connection:keep-alive, который говорит о том, что сервер поддерживает постоянное соединение и он оставил соединение открытым для того чтобы можно было загружать следующие ресурсы.
Постоянное соединение в HTTP 1.1
В версии протокола HTTP 1.1 все соединения по умолчанию считаются постоянными. Использовать заголовок Connection:keep-alive не обязательно, но многие браузеры и серверы до сих пор это делают. Однако, если клиент не вставим заголовок Connection:keep-alive в запрос, соединение все равно останется открытым. Если по каким-то причинам клиент считает, что соединение нужно разорвать, то он может использовать заголовок connection close.
Недостатки постоянного соединения
Хотя постоянные HTTP соединение позволяет увеличить скорость передачи данных от web сервера к клиенту, поддержание этого соединения требует ресурсов на сервере. Ресурсы сервера ограничены, и если клиент открыл соединения и его не использует, то этих ресурсов не хватит другим клиентам, особенно это плохо для высоконагруженных серверов, к которым поступают несколько сотен или тысяч запросов в секунду.
Поэтому современные web-серверы автоматически закрывают соединение, если оно не используется в течение какого-то времени, как правило от 5 до 15 или 20 секунд. Обычно этого времени достаточно для того чтобы загрузить web-страницу и все сопутствующие ей ресурсы.
Конвейерная обработка HTTP (pipelining)
Другая технология, которая позволяет увеличить скорость передачи данных HTTP, называется HTTP pipelining, по-русски конвейерная обработка. Она заключается в следующем, после того как сделали запрос на получение HTML странички, получили ответ, браузер проанализировал ответ и извлек перечень всех ресурсов которые нужно загрузить с сервера.
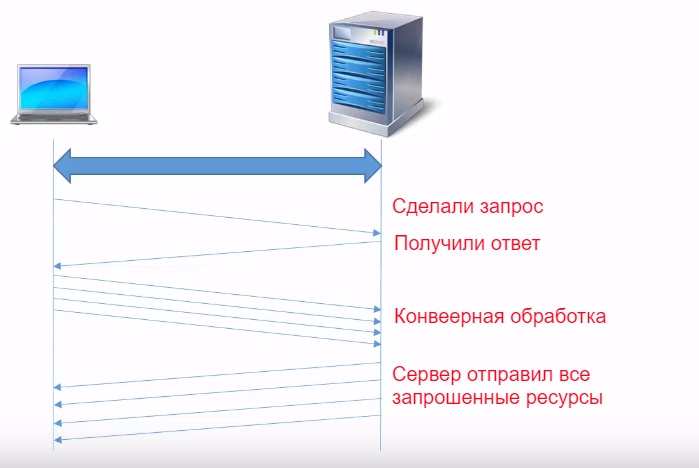
Конвейерная обработка позволяет передать от клиента серверу сразу несколько запросов для загрузки ресурсов не дожидаясь получения ответа.
Сервер получив несколько запросов, в ответ отправляют сразу все запрошенные ресурсы. Недостатком технологии является то, что ресурсы должны передаваться в том же порядке в котором пришли запросы.
Однако если с загрузкой какого-то ресурса возникли проблемы, то другие ресурсы передавать нельзя даже если они уже готовы к передачи. Это проблема решена в протоколе HTTP 2.0, где можно нумеровать запросы и передавать ресурсы от сервера клиенту в любом порядке. К сожалению конвейерная обработка на практике используется достаточно редко.
Несколько HTTP соединений
Еще один вариант, как можно увеличить скорость загрузки web-страниц это использовать несколько HTTP соединений. Клиент открывает несколько соединений с web сервер и каждое соединение используется для загрузки разных ресурсов.
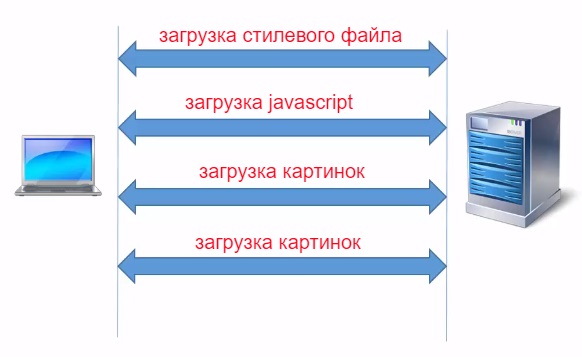
Например, первое соединение для загрузки стилевого файла, следующие соединение для загрузки javascript и другие соединения для передачи различных картинок. Каждое такое соединение может быть постоянным и использоваться для загрузки нескольких ресурсов, а также внутри таких соединений можно использовать HTTP pipelining. Почти все современные браузеры используют несколько HTTP соединений как правило от 4 до 8.
Кэширование в HTTP
Рассмотрим другой механизм, созданный для увеличения скорости загрузки веб страниц с использованием постоянного соединения HTTP кэширование. Сейчас многие современные web браузеры могут сохранить страницу на локальном диске, если она изменяется редко, и показывать страницу из каша на диске, а не загружать ее с сервера.
А также возможно кеширование не полностью web-страницы, а отдельных ресурсов, которые изменяются реже. К таким ресурсам относятся картинки, например, если на сайте есть логотип компании, то вряд ли он изменяется очень часто, это также могут быть таблицы стилей, библиотеки Java Script. Дополнительным преимуществом является то, что такие ресурсы используются ни одной страницей, а несколькими страницами на сайте.
Кэширование требует место на локальном диске компьютера, но сейчас это не составляет проблем. Поддержка кэширования ресурсов встроена прямо в протокол http. Основная проблема заключается в том, что браузеру необходимо определить можно ли брать страницу из кэша, или страница изменилась и необходимо обращаться за ней к web –серверу. В http для этой цели используется заголовок Expires. Этот заголовок web-сервер добавляет к ресурсу, когда передает http ответ и заголовок говорит о том, до какого времени можно хранить ресурс в кэше.
Заголовок Expires:
Expires: Sun, 12 Jun 2016 10:35:18 GMT
Указывает, до какого времени можно хранить ресурс в кэш
Web-сервера навсегда устанавливают этот заголовок
В примере ресурс можно хранить до 12 июня, после этого ресурс устареет и необходимо снова обращаться к серверу. Однако не все web-серверы устанавливают этот заголовок. Если заголовок Expires не установлен, то браузер может использовать некоторые Эвристики. Например, он может использовать поле last-modified в котором указываются дата последнего изменения ресурса.
Last-Modified: Wed, 25 May 2016 06:12:24 GMT
Если страница долго не менялась, то скорее всего можно загрузить ее из кэша
Возможны ошибки
В примере 25 мая 2016 года. Если страница долго не менялось, то можно предположить, что в ближайшее время она не изменится, и можно брать ее копию из кэша. С другой стороны при таком подходе возможны ошибки. Например, наша эвристика может заключаться в том, что мы берем из кэша те страницы, которые не менялись в течение двух недель, но страница может меняться 1 раз в месяц.
Запрос GET с условием
Протокол http содержит другой подход, который позволяет определить изменилась страница или нет. Для этого клиент должен отправить серверу запрос GET с условием, или по-английски Conditional GET. Клиент передает запрос GET с условиям, в ответ сервер может сказать, что страница не изменилась, тогда браузер берет версию страницы из кэша, а если страница поменялась, то web-сервер передаст измененную версию web-страниц.
Как работает запрос Conditional GET
При первом обращении к ресурсу, браузер посылает обычный запрос GET и сохраняет результат в кэш. Conditional GET можно использовать только если в http ответе установлен заголовок Last-modified, в котором указана дата последнего изменения ресурса.
В следующий раз, когда браузер будет обращаться к серверу за тем же самым ресурсом, он уже будет использовать запрос Conditional GET, в этом запросе используется дополнительный заголовок if-Modified-Since, в этом заголовки указывается дата изменения ресурсов, это дата как раз берется из значения заголовка last-modified, который передал нам сервер.
Сервер может передать два варианта ответа на Conditional GET запрос. Если ресурс не поменялся, то сервер передает короткое сообщение со статусом 304 Not Modified. Это сообщение, также может включать дополнительные заголовки по управлению кэша. Сам ресурс при этом не передается, так как актуальная копия есть в кэше браузера. Если же ресурс поменялся, то измененная версия ресурса передается полностью, при этом используется статус http ответа 200 OK.
В протоколе версия HTTP 1.1 появилась другая возможность проверить изменился ресурс или нет. Для этого используется entity tag или сокращенно ETag, это код который генерируется на основе содержимого ресурса? как правило это хэш-код или что-нибудь подобное.
Web-сервер при отправке ресурса, добавляет этот код в заголовок ETag, если ресурс изменился, то значение ETag также поменяются. ETag удобно применять, если web-сервер может передавать различные варианты одной и той же страниц.
Например, на разных языках, в этом случае дату изменений использовать нельзя, так как страницы на разных языках могут быть изменены в одно и тоже время, а ETag вполне подходит. Если мы хотим использовать ETag в conditional GET то вместо заголовка if-Modified-Since мы должны указывать If-None-Match. Вот пример: If-None-Match: 57454284-3d8f
В стандарте HTTP 1.1 появился новый заголовок Cache-Control с помощью которого можно более гибко управлять кэшированием. Заголовок Cache-Control может содержать несколько различных элементов.
Cache-Control: private, max-age=10. В этом примере используется два элемента private и max-age = 10 разделенное запятой.
Что можно использовать в заголовке Cache-Control
- значение no-store, говорит о том, что ресурс нельзя сохранять в кэш;
- no-cache, говорит о том, что и ресурсы сохранять в кэш можно, но для его использования необходимо выполнить запрос conditional GET, и загружать ресурс из кэша только в том случае если он не изменился на сервере;
- public, говорит о том, что информация может быть доступна всем и ее можно кэшировать, это значение удобно использовать совместно с http аутентификацией, так как по умолчанию при аутентификации кэширование не используется;
- private сообщает о том, что страница может быть сохранена только в частном кэша браузера, но не в разделяемых кэшах;
- max-age устанавливает время хранения ресурсов кэша в секундах, используется для замены заголовка expires.
Web прокси сервер (proxy server)
Данные web могут быть закешированы не только на браузере, который установлен на персональный компьютере клиента, но также и в других местах. Например, может использоваться прокси-сервер. В этом случае клиенты обращаются к web-серверам не напрямую, а через прокси-сервер. Прокси-сервер сам подключается к web-серверам в интернет, получает ресурсы, сохраняет их в кэш и потом передает клиентам.
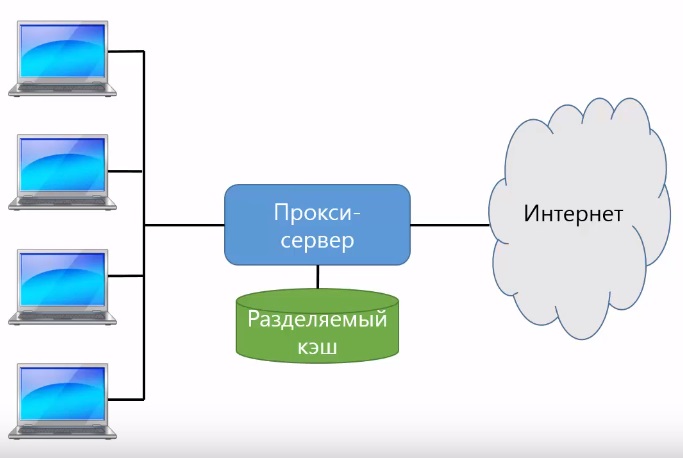
Если большое количество клиентов, которые работают с прокси часто обращаются на одни и те же сайты, то использование прокси-сервера позволяет значительно повысить скорость загрузки web-страниц. Так как необходимые ресурсы уже могут быть в разделяемом кэше, потому что их кто-то уже запрашивал.
С другой стороны пользователи, как правило заходят на большое количество разных сайтов, и все эти обращения также записываются в кэш прокси-сервера, хотя потом они используется очень редко или вообще не используются. Это значительно снижает эффективность работы прокси-серверов.
Обратный прокси сервер (reverse proxy)
Есть другой вариант прокси-сервера, который называется обратный прокси или reverse proxy. В отличии от обычного прокси, он устанавливается не со стороны клиентов, а со стороны web-серверов.
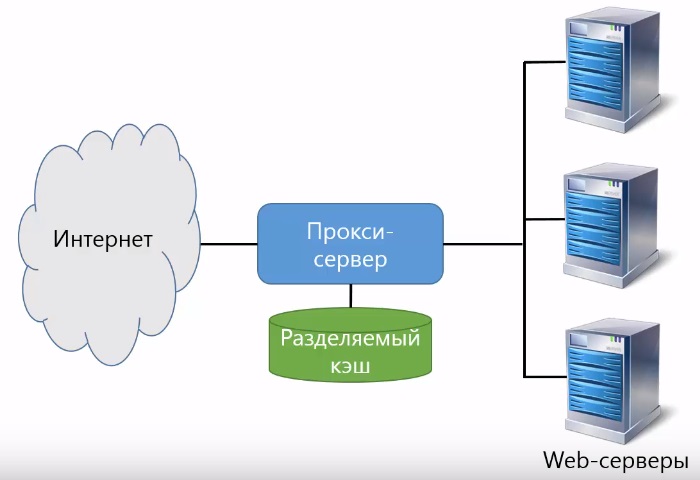
Обратный прокси-сервер принимает запросы от клиентов web-браузеров из интернета и передает их на web-сервера. При этом прокси-сервер, также кэширует ответы web-серверов, он кэширует не только статическую информацию, но и динамические страницы, которые получаются в результате работы программ на web-серверах. Эти программы часто обращаются к базам данных или к другим ресурсам, и работают достаточно медленно. Поэтому кэширование результатов работы этих программ в виде готовой страницы на обратном прокси-сервере существенно повышают скорость загрузки web-страниц.
Заключение о протоколе HTTP
Итак, постоянное соединение HTTP позволяет использовать одно и то же TCP соединение для загрузки нескольких ресурсов. Это позволяет сократить время на установку соединения TCP, нет необходимости каждый раз проходить процедуру трехкратного рукопожатия.
В стандарте http 1.0 не было поддержки постоянного соединения, эта возможность была добавлена уже после публикации стандарта в виде заголовка connection: keep-alive. В стандарте http 1.1 все соединения по умолчанию постоянны и заголовок connection: keep-alive использовать не обязательно.
Мы рассмотрели кэширование web и его поддержку в протоколе http. Если в страницу, ввести какой-то ресурс из кэша, то загрузка происходит значительно быстрее, чем если мы обращаемся за тем же самым ресурсом в сеть. Необходимо иметь ввиду, что данные кэшируется не только в кэше web-браузера, это так называемый частный кэш, который является отдельным для каждого пользователя, но и данные могут быть закэшированные в других местах. Например, на прокси-серверах, на обратных прокси-серверах, которые копируют запросы большого количества пользователей и такой кэш называется разделяемый.

